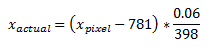It's really hard to write when you are not in the mood to do so. It took me a long time to finally face the fact that this activity is due today and there's no choice for me but to work on it. This activity requires a great deal of effort and patience in reading the histories of all image types! But it's also quite interesting to know more about the reasons why they had to invent/create a lot. What could be the reason why we are still given a choice of what format to use when saving images? Haha. I remember when I was asked by my brother Orly to review his powerpoint presentation for his graduate thesis defense. Much of my attention was on the pictures and plots. I got really really OC about his figures so I asked him to revise some of the images. I remember him saying "Save as .tif para walang mawalang info, wag jpeg", and all I could think was how can you compress an image without losing information? If that's possible then there's really no reason to use other formats anymore! Haha. I was very ignorant back then. So anyway, enough with the back story. Let's get to the real thing.
The title of this blog is "understanding photographs". For us to be able to really understand them, we must learn the different types and formats of images as well as their history. We start then with the four basic types and these are the following:
1. Binary
Binary images consists of values either 1 or 0 per pixel. They can either appear as black and white or it can also be any other two set of colors. Typically, the pixels with values 1 appear as white and pixels with values 0 appear as black. The figure of the hugging zebras shown below is obtained from [1], and the pixel values of an area is manually added to demonstrate the pixel numbering in the original image.
The properties of the original image obtained from the web are the following:
It always struck me how information can still be stored and presented in a way that requires only two colors.
2. Grayscale
Another basic type of image is the grayscale. This type has pixel values in the range [0, 255]. Since each pixel consists only of a single value, grayscale stores the information about the intensity of the image where the brightest value is 255 (white) and the darkest is 0 (black). For this reason, grayscale images are also called monochromatic since they are only composed of a single color of different shades. The picture shown below was captured by my brother Jay Jay Tarun when he and my sister had a vacation in Rome, Italy.
3. Indexed Images
Indexed image is a type of image that stores 8-bit of information as opposed to true color images that's composed of at least 24-bit. This limited size allows file transfer faster and efficient. In this type, the information is not stored per pixel, but in a separate vector called the palette. This is a set of colors specific for the image itself. Each pixel contains information about the index on the image' corresponding palette. [12]
These types of images are often used as an option/effect in many easy photo editing software. I'd like to think that indexed images are like truecolor images but their colors are not "continuous". It looks like the combination of each pixels were not smoothened.
An example of an indexed image and a truecolor image
4. Truecolor Images
Truecolor images must be the most common image we encounter in our everyday life. This format, as its name suggest, shows the true color of the image the same way that we see it live with our own eyes. It stores details such as luminosity, brightness and the likes. Each pixel usually stores 24-bit depth of color information, 8-bits each for red, green and blue. An example of a true color image is the flower shown in the above picture.
To better appreciate true colors, we try to compare the image of the flower with the other image types and we can do it by converting it to the other formats. I used Scilab in converting the images The original file size of the true color image is 1.30 Mb which is quite large.
The truecolor image of a flower converted to different types with their corresponding histogram at the top
I converted the truecolor image to grayscale and binary using Scilab, and the code for doing this is shown below.
Since grayscale images only contain monochromatic colors, it is expected that the file size should decrease since the original RGB combination was flattened to a single layer without losing the information on brightness. The information is represented by the different shades of gray in the image. To know more about this information, I obtained the histogram of the image and is shown below:
For the conversion to indexed image, I used GIMP>Mode>Indexed. The size also decreased.
In converting a truecolor image to binary, one of the requirements for the syntax im2bw is the threshold. To explore this further, I created the following images of increasing threshold. As can be observed from the figure below, there is a certain threshold to which a truecolor image could retain the information. In the example below, the threshold range 0.5 to 0.6 is the most informative. A threshold that is too small would result to an image with a majority of white, while a very high threshold would you an image with a majority of black depending on the true image you have.
Binary image of different threshold
In all of these file types, we can observe that the true color type occupies the highest memory.
Now, what happens if we crop an image? Would the size decrease too? To know this, I cropped an image with a known size and compared it to the size of the cropped image.
Cropped image
As intuition would tell us, the size of the cropped image indeed decrease. To make the cropping of the image consistent, I exported the image in the same file format. This method is just basically scaling the image size when compressing it.
These file types are sometimes not enough especially if what we need are more informative and more appealing to the eyes. Other subjects such as the sunset, galaxies and volcano lava need a more advanced type in order to capture and give justice to the appearance of the subjects in real life. These advanced type are the following:
1. High dynamic range (HDR)
True color images are normally stored in 24-bit, with 8-bit each grayscale recording [3]. HDR images require more of this to capture the contrast in the light and dark areas of a picture. This is done by taking a picture of a subject multiple times at different exposure levels, and then stitching them together to produce a more detailed image.[2]
High Spectral image obtained from
here [2]
2. Multi or hyperspectral image
Normally, true-color images have normal bands of 3 (red, blue and green). In multi-spectral images, images are also captured at a specific band of the electromagnetic spectrum, sometimes even for frequencies that are not part of the visible spectrum such as the infrared. These images of the same scene are then stacked to create a single image. These are normally used in satellite images (hyperspectral). An example of a multispectral image is shown below taken from [5]
3. 3D images
Information of a 3D image can also be stored in different ways. An example of a 3D CT scan is shown below. 3D images are always used in medical fields and enterinatinment.
4. Temporal Images or Videos
A normal image can just take a single snapshop of what really happening. They say a picture paints a thousand words. Now imagine if we have a video of a scene, would it speak a thousand more words, or would it actually limit the possible happenings in our own imaginations? Would it give us enough leeway to explore and think more about the captured moments? An example of a video is embedded below.
Everything has changed, Ed Sheeran ft. Taylor Swift
Aside from these image types, images can also be classified according to file formats. We then go back to the question from the start of this blog. What's the use of saving an image file to a specific format? What makes all the difference? One of the main reasons why users convert images into different formats is to save memory. Although the sizes of images (KB-MB) are comparably small compared to the amount of storage we have today, it is important to note that these images are also sent over the internet, and doing so would require a limited size. Two types of compression have been developed through the years. Their main difference is the characteristic to retain information. These are the lossless image compression and the lossy image compression. [3]
To start with, we have to enumerate the most common formats we have today. I could attest that jpeg must be the most common and familiar image format. This type is the most used especially if an image requires a great deal of color while maintaining the quality and size of the image. To understand these formats, let's try to dive in to their history and several trivia about each one.
1. JPEG - Joint Photographic Experts Group
This type of format is the most widely used in digital cameras and in World Wide Web. It is an example of a lossy image compression which uses a compression technique based on the discrete cosine transform. JPEG compression gives the user a luxury to choose the amount of compression with trade-off on the quality and size of the image.[7]
2. BMP - bitmap image file or device independent bitmap (DIB) file format
First, we define what is bitmap. Bitmap is "a mapping from some domain (for example, a range of integers) to bits, that is, values which are zero or one." Basically, bitmap is an array of bits. This array stores information and forms a digital image. [8]
3.
GIF - Graphics Interchange Format
This format was introduced in 1987 and supports up to 8-bit per pixel. It is also an example of a lossless image compressionn which was LZW compression that allows for efficient run-length encoding. It supports animation and up to nowadays, this is the format that is very well known when it comes to saving animated images. [9] Because of its limited support on the number of colors (256), the image shown below demonstrates "discontinuous" color representation as the true color image of the grapes is converted to GIF.
4. TIF - Tagged Image File format
This format is popular among photographers and artists and currently it is under the control of Adobe Systems. Originally, the tiff is created to give a unifying format for a scanned image file. During these times, desktop scanners could only handle a binary image format, and thus tif was just binary. As the technology on scanners blossomed, the tif evolved to handling grayscale images as well as color images. [10] The best thing about tif is that it is a lossless image compression technique which makes it very efficient in preserving both quality and the size of the image.
5. PNG - Portable Network Graphics
This format is the most widely used lossless image compression form in the World Wide Web. It was created as an improved version of the GIF. It is designed to share the information/photos across the web for basic use and not for major photographic needs. Although it was a successor of the GIF format, it does not support animation. Instead, it improves the number of color display of the GIF (at most 256) to more. [11]
The conversions of the images posted here would not have been possible without Scilab. I used different syntax to convert the image I have to the type of image I prefer such as the im2bw, rgb2gray and the likes. Aside from right clicking the image to obtain its properties, we can also use scilab as well as GIMP to obtain the Image properties. In scilab, we can just use the syntax imfinfo.
And that's it! Although this activity is more tedious than the previous ones, it took me a number of times to edit the blog before actually submitting it. For this, I give myself a 12/10 for giving a description for each of the basic types, and exploring the effect of thresholding binary images.
References:
[1] Zebras Hugging Poster for Binary Options Trading Retrieved from http://www.zazzle.com/zebras_hugging_poster_for_binary_options_trading-228649002521143770 on June 18, 2013
[2] High dynamic range from http://en.wikipedia.org/wiki/File:Leuk01.jpg on June 19, 2013
[3] Dr. Maricor Soriano, A3 – Image Types and Formats
[4] Multi-spectral image from http://en.wikipedia.org/wiki/Multispectral_image Retrieved on June 19, 2013
[5] Multispectral Imaging Moves into the Mainstream from http://www.osa-opn.org/home/articles/volume_23/issue_4/features/multispectral_imaging_moves_into_the_mainstream/#.UcaAv_kwdsl on June 19, 2013
[6] 3D CT scan poster from http://www.cafepress.com/+arteritis_3d_ct_scan_large_poster,664647321 on June 19, 2013
[7] JPEG from https://en.wikipedia.org/wiki/JPEG on June 19, 2013
[8] BMP file from http://en.wikipedia.org/wiki/BMP_file_format on June 19, 2013
[9] Graphics Interchange Format from http://en.wikipedia.org/wiki/Graphics_Interchange_Format on June 19, 2013
[10] Tagged Image Format from http://en.wikipedia.org/wiki/Tagged_Image_File_Format on June 19, 2013
[11] Portable Network Graphics from https://en.wikipedia.org/wiki/Portable_Network_Graphics on June 19, 2013
[12] What's an index? What's a palette? from http://www.scantips.com/palettes.html on June 19, 2013